13 Lab 13 - Densities and distances
13.1 Guided Exercise 1 - Obtaining and organising the data
For this set of exercises, we will be working with crime occurrence data (arrest incidents) for the city of New York (USA), for the year 2023. Imagine you have been hired to support an analysis of NYC criminality to help better manage police resources and reduce crime.
The data package for this exercise can be downloaded here, and has been obtained from the City of New York Police Department website and the NYC Open Data hub, and contains the following:
Arrest incidents for the year 2023, as a point vector shapefile - derived from a shapefile containing all arrest incidents from 2013 to present.
A polygon vector shapefile with the boundaries for the NYC neighbourhoods.
A polygon vector shapefile with the boundaries of each Police Precinct in NYC. Each police precinct is the responsibility of a different police chief and team.
A point vector shapefile with the locations of all police stations in NYC. Most precincts have one station, with a few exceptions in the case of additional speciality police stations such as mounted police.
- First, download and extract the data package, and create a new folder and QGIS project for this lab. Import all four layers to your project. If you wish, add the OpenStreetMap or some other web layer from the
QuickMapServicesplugin to help with context and navigation.
Zoom to the full extent of the arrests layer - can you spot a problem with it? How can you fix it?
13.2 Guided Exercise 2 - Looking for crime hotspots
The first question you have been asked is where the crime hotspots in the city are, meaning the areas with the largest density of occurrences. The word density usually refers to a count of things divided by some area or volume measurement. For example, population density is number of people per area; oxygen density in normal atmospheric conditions is 1.43 grams / litre.
In GIS, density will be usually related to counts of ‘things’ over areas - the more things happening per unit area, the higher the density. This is often called hotspot analysis in GIS, where the hotspots are areas of remarkably high density. And the main tool used for that is known as Kernel Density Estimation (KDE). I have made a video explanation on KDE that you can watch on Canvas. We will now learn about two ways of generating density maps.
- The first way to generate a density map is to change the layer
Symbology(see image below). Select the crime layer and go toProperties > Syymbology, then change the symbology type fromSingle SymboltoHeatmap. PickRedsas theColor ramp, and aRadiusof 1000, changing the radius unit fromMillimiterstometers at scale. ThenApplyandClose. It will take a bit of time to change the appearance.
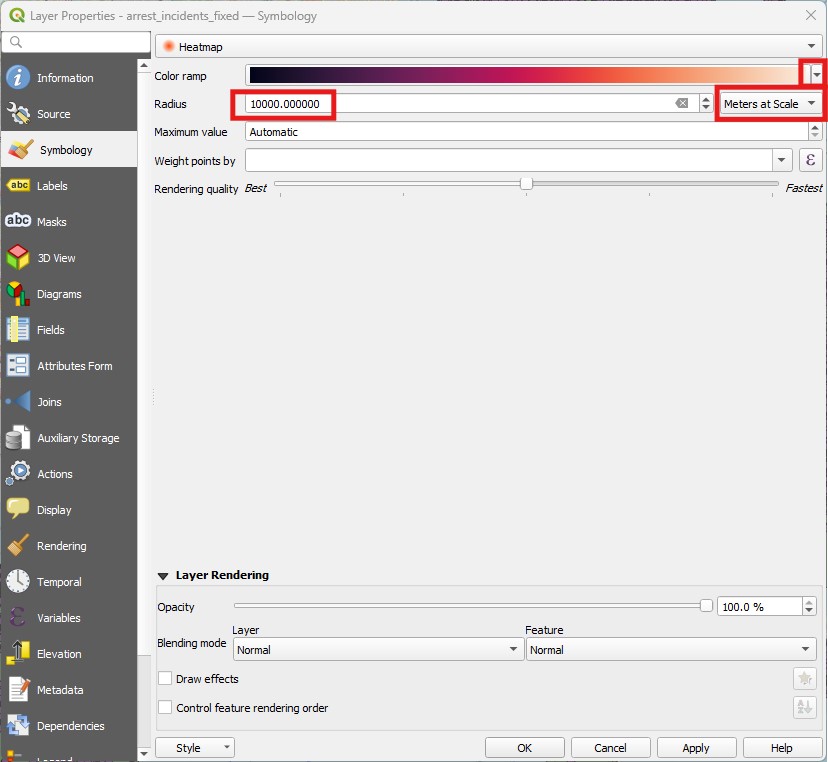
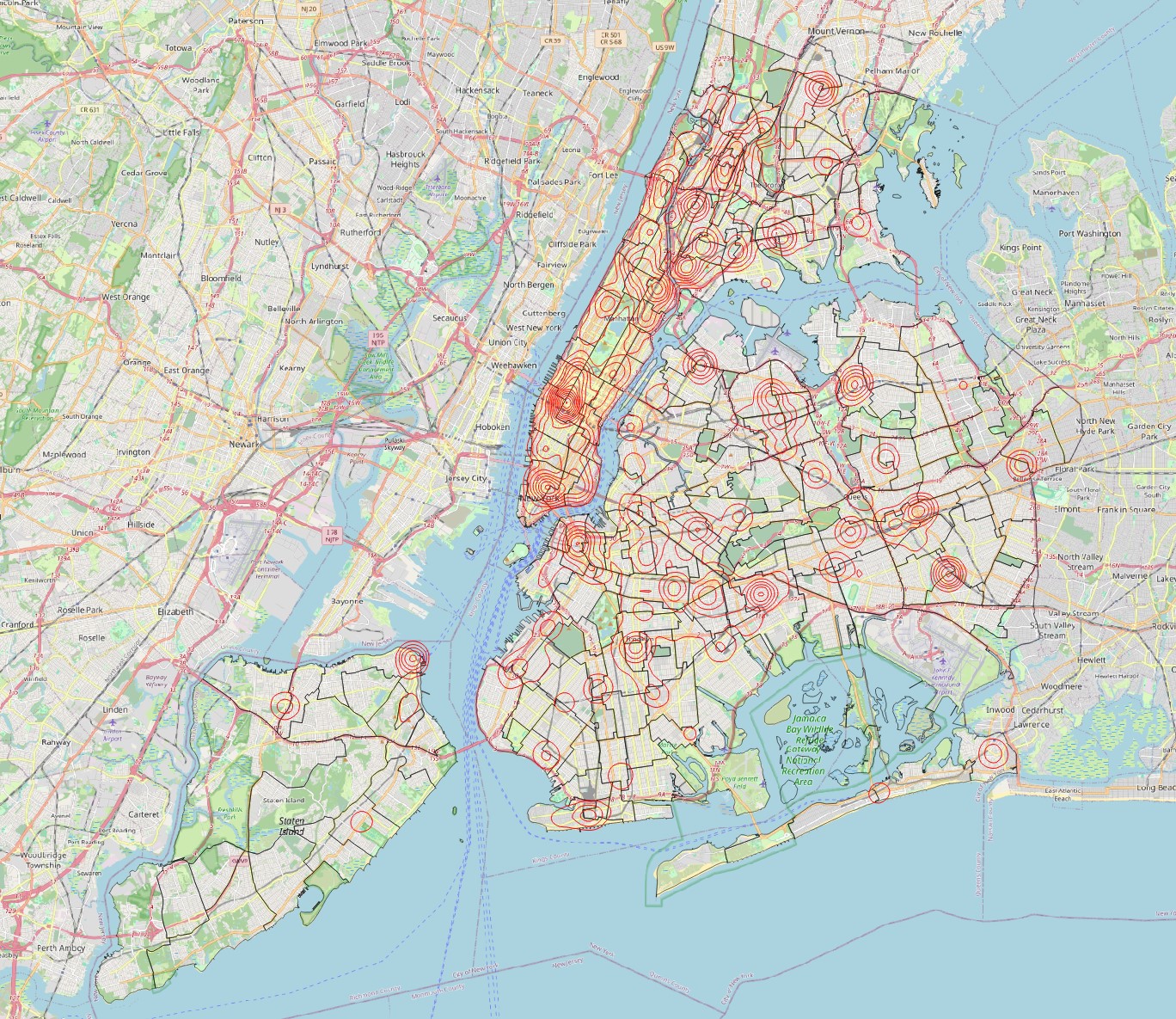
- To add some context, place the neighbourhoods layer on top of it, with no fill and a dark outline. It should look somewhat like this:
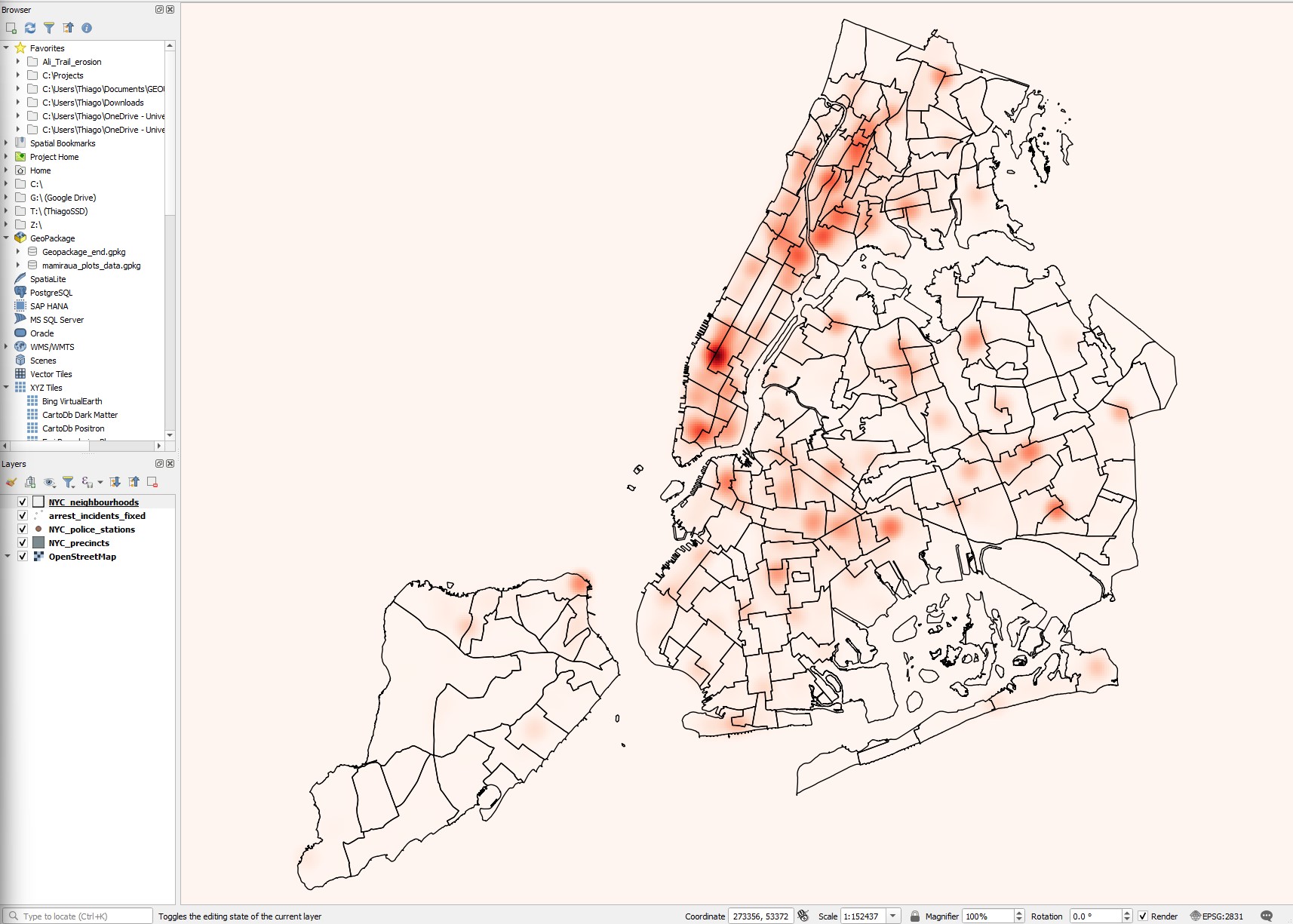
Based on the hotspot map, which police precincts seems to have their hands full with crime occurrences? And what neighbourhood is it?
What is the CRS of the datasets (which should be also set as the CRS for the project)? What datum, projection and coordinate system does it use?
The heatmap symbology is useful for a quick inspection, but it is also restrictive - and it needs to redraw every time you zoom or pan the map, so it can be annoying. It would be more useful if the heatmap was an actual layer. We can create such permanent heatmap using the Heatmap (Kernel Density Estimation) tool.
- Launch the
Heatmap (Kernel Density Estimation)tool in theProcessingpanel, under theInterpolationcategory. It will show a new window like this:
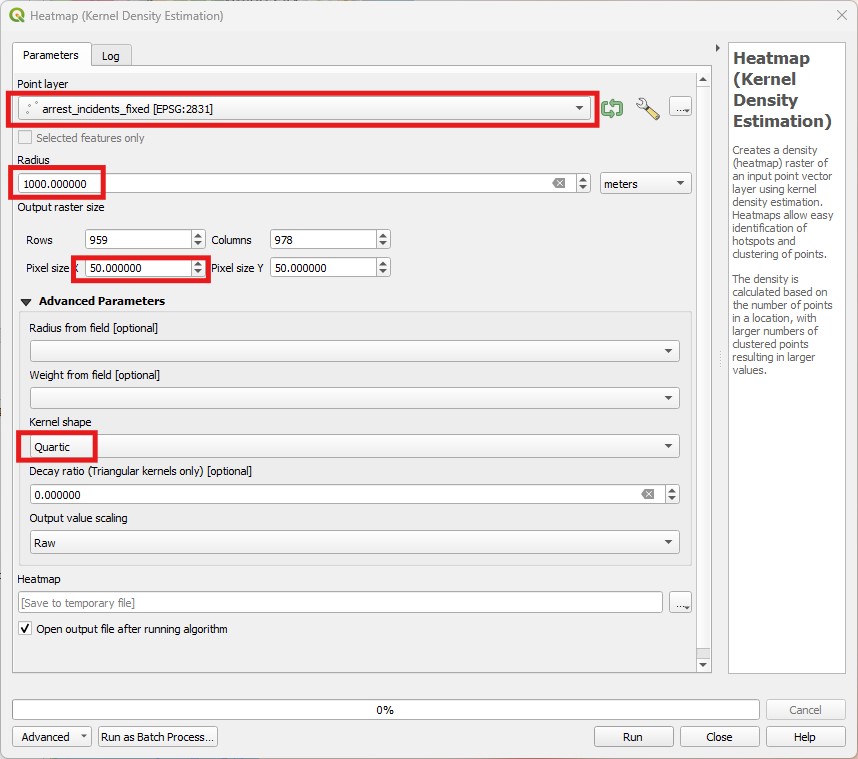
Pick the crime layer as your
Point Layer, then set a radius of 1000meters(or 1kilometers). One important additional option here is that we get to set the resolution (pixel size) of our output raster density map. Smaller pixels will look smoother, but will result in larger files and longer processing times. The units here are the same as the layer CRS, so let us use50meters for bothPixel XandY. Leave theKernel Shapeas quartic and the other options as default. Save your result in an appropriate location with the namecrime_density_1km_quartic_50m.tif.Notice how the output of
Heatmap (Kernel Density Estimation)is a raster, and that nodata values are used for regions that are not within 1km of any point (unlike theHeatmapsymbology, which paints everything including the zero). Since it is a raster, we can style it with symbology options just the same as any raster. Pick aSingleband pseudocolorcolour ramp for your hotspots, and use the sameRedscolour ramp you used for theHeatmapsymbology in the previous steps.
Does the heatmap produced as a layer look the same as the heatmap produced by the symbology?
- To demonstrate the issue above, generate a second heatmap layer, this time using 5km as
Radius, aPixel sizeof100metres, theUniformkernel shape, andScaledoutput values. Save it ascrime_density_5km_uni_100m_scaled.tif. The style it with theRedscolour ramp as well.
Not only the layer looks very different, but the actual locations of the hotspots seem to have changed, and the density values are also very different. It always takes a lot of trial and error to converge on a KDE estimation that is sensible for the problem at hand.
If you’d like, try different combinations of radii, kernel shapes and pixel sizes. Once you are done, remove them all from your project, leaving only the first density map we created (radius 1000, quartic kernel, pixel size 50m). Also, change the symbology of the crime points layer back to
Single Symbol.We can now use tools we already know to associate the crime density information to the precincts and neighbourhoods. Using
Zonal Statistics, extract themeanandmaximumdensity values for each precinct. Then make two map visualizations, one colouring the polygons by average crime density, and the other by maximum crime density. Do the same for the neighbourhoods layer. This is what they should look like:
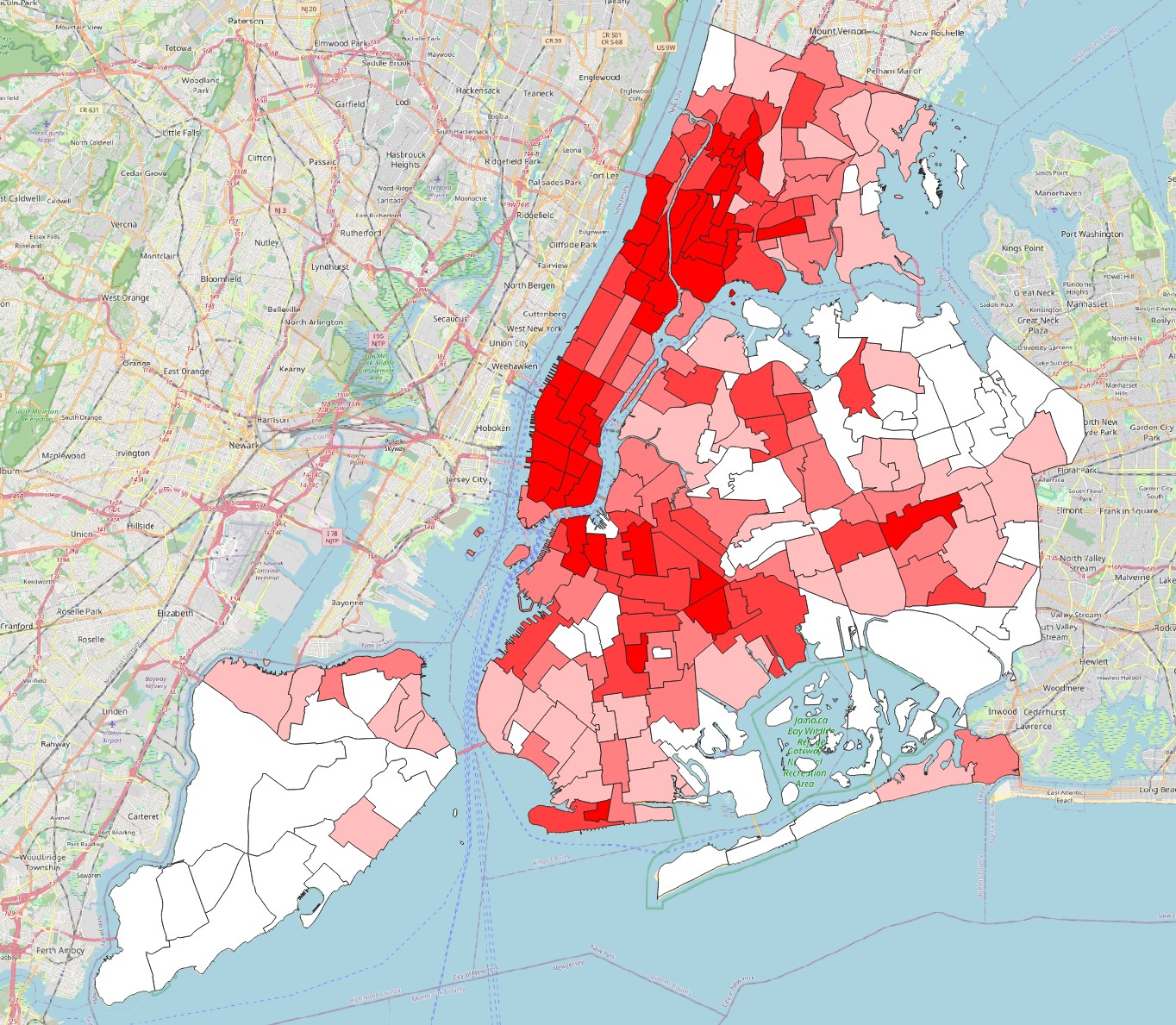
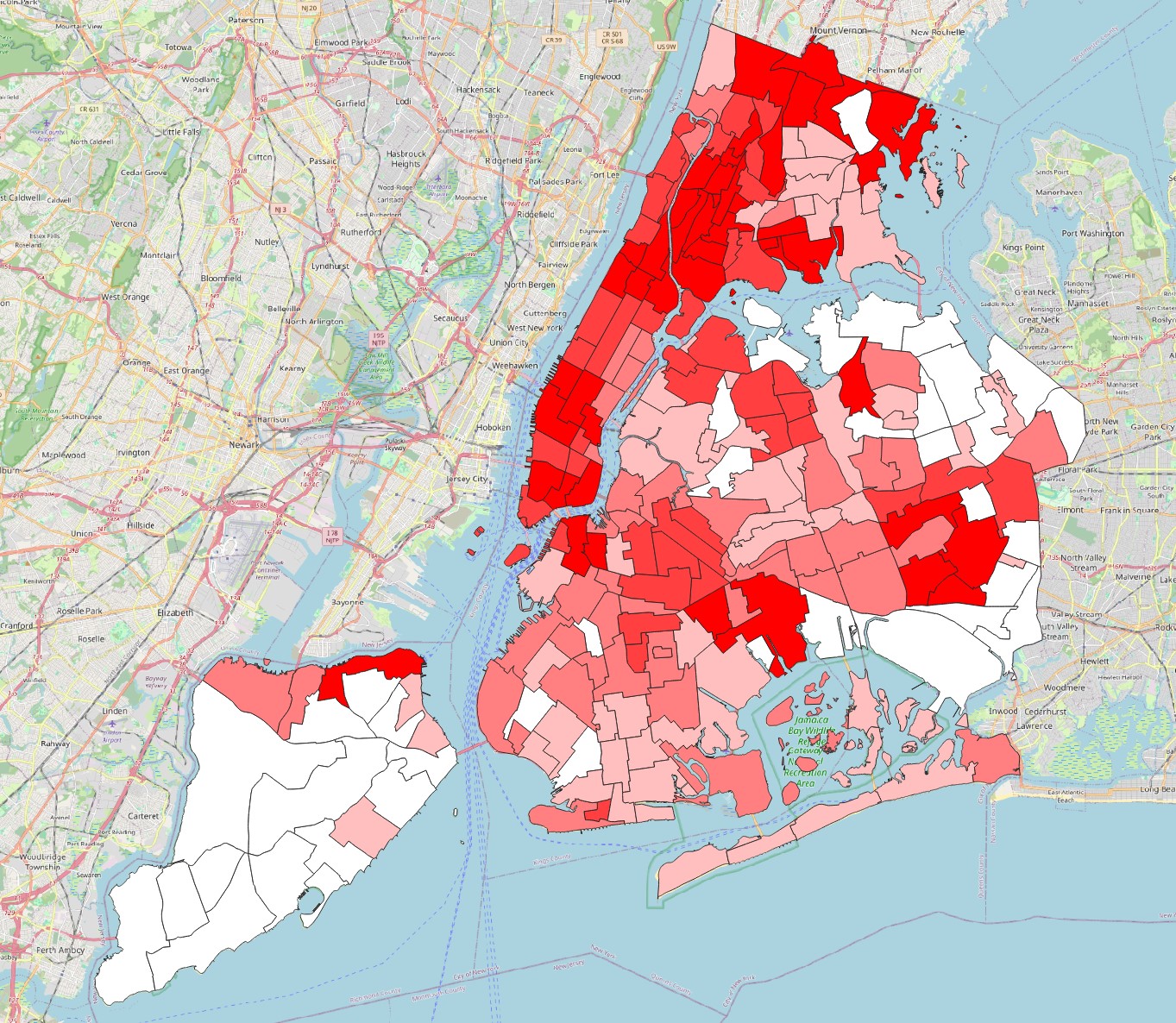
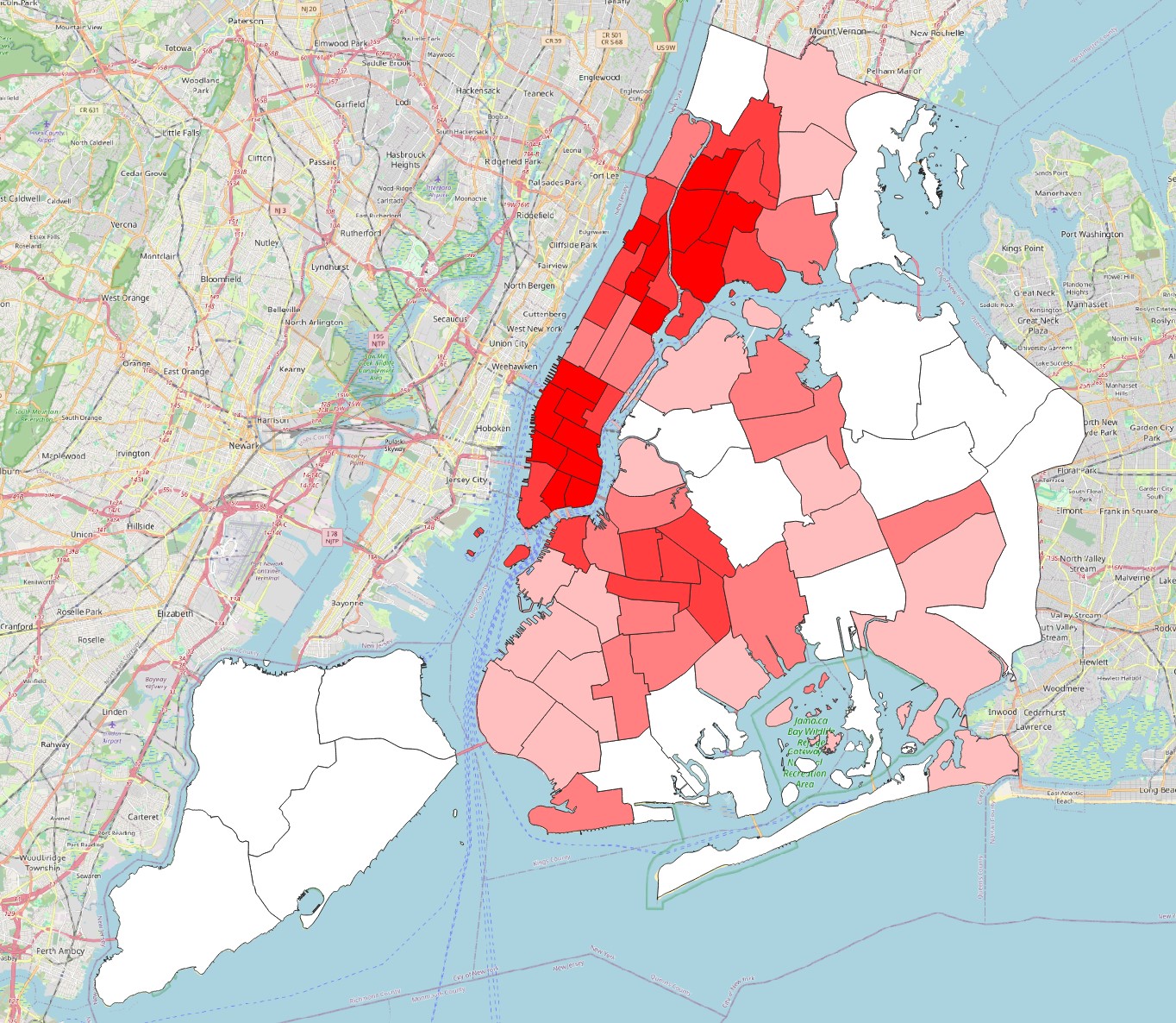
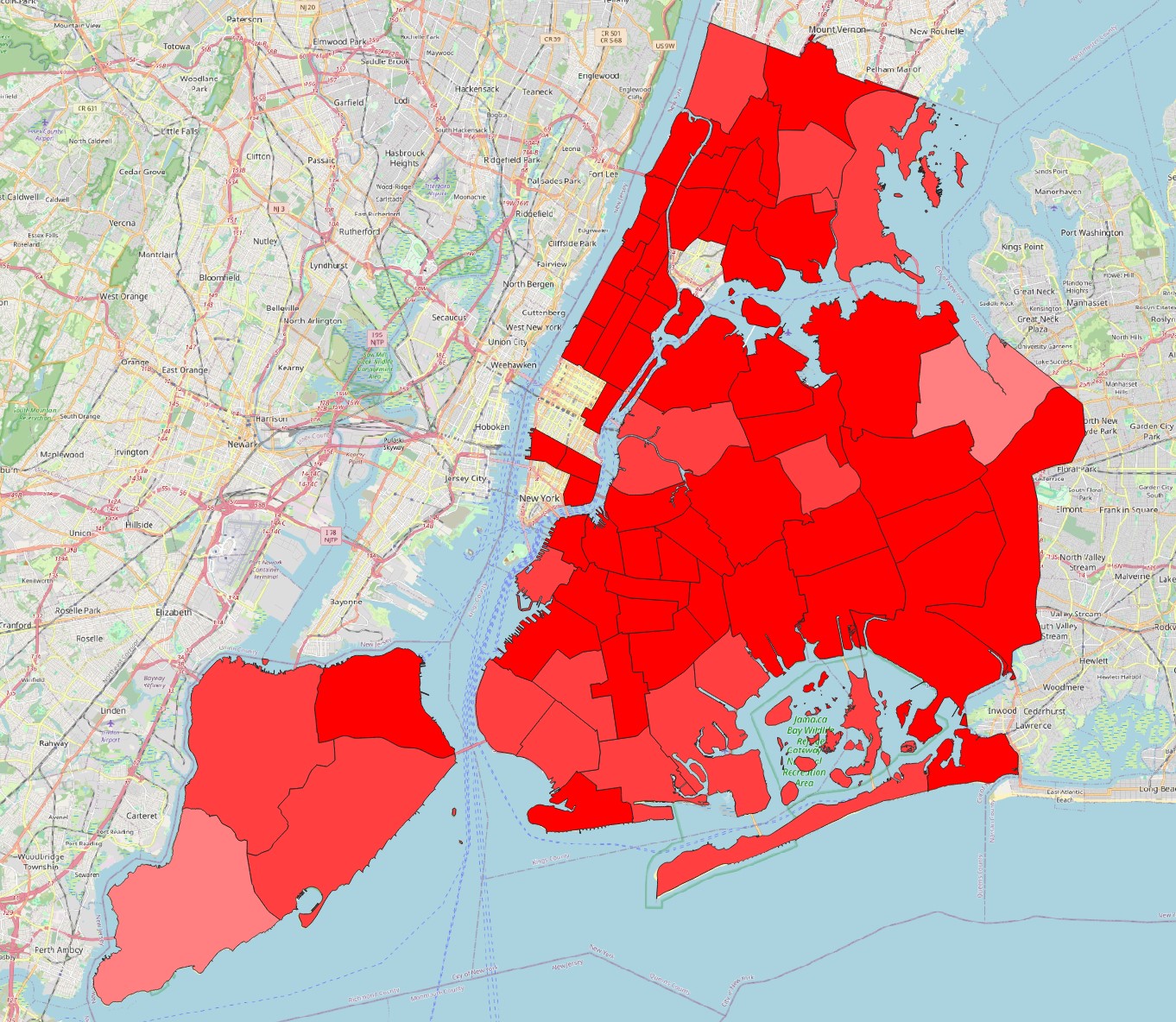
Which precinct and neighbourhood seem to be the most problematic in terms of crime, i.e. have the highest average and/or maximum crime density?
13.3 Guided Exercise 3 - Weighted Kernel Densities
The analysis above seems good, but one thing we are not considering is the type of crime. Our incident dataset includes several types, from traffic violations to serious crimes. The law_cat_cd field contains codes identifying the type of incident.
What are the unique existing values for the law_cat_cd field?
Perhaps if we give different weights to crime according to their seriousness, our results may change. But for that, we need a numeric attribute that indicates the weight to be given to each type of crime. We could use the Field calculator multiple times by selecting each type of crime and filling a new attribute with the respective number, but there is a quicker way: the CASE WHEN conditional operator.
Open the attribute table for the arrest incidents layer, and then open the
Field Calculator.Then enter the
CASEexpression like it is shown on the figure below. The syntax is quite self explanatory: once you typeCASE, you open what we call a block. Inside the block, you then list a series of conditions (i.e. cases) for what numeric value the new attribute should have for different string values oflaw_cat_cd. At the last line in the block you add theELSEoperator, meaning that if none of the cases are matched, then the new attribute should have a value of 0. That would include theNULLs and the9values that are not informative to us. You then close the block withEND. We have more than 600k entries, so it will take a while to run!
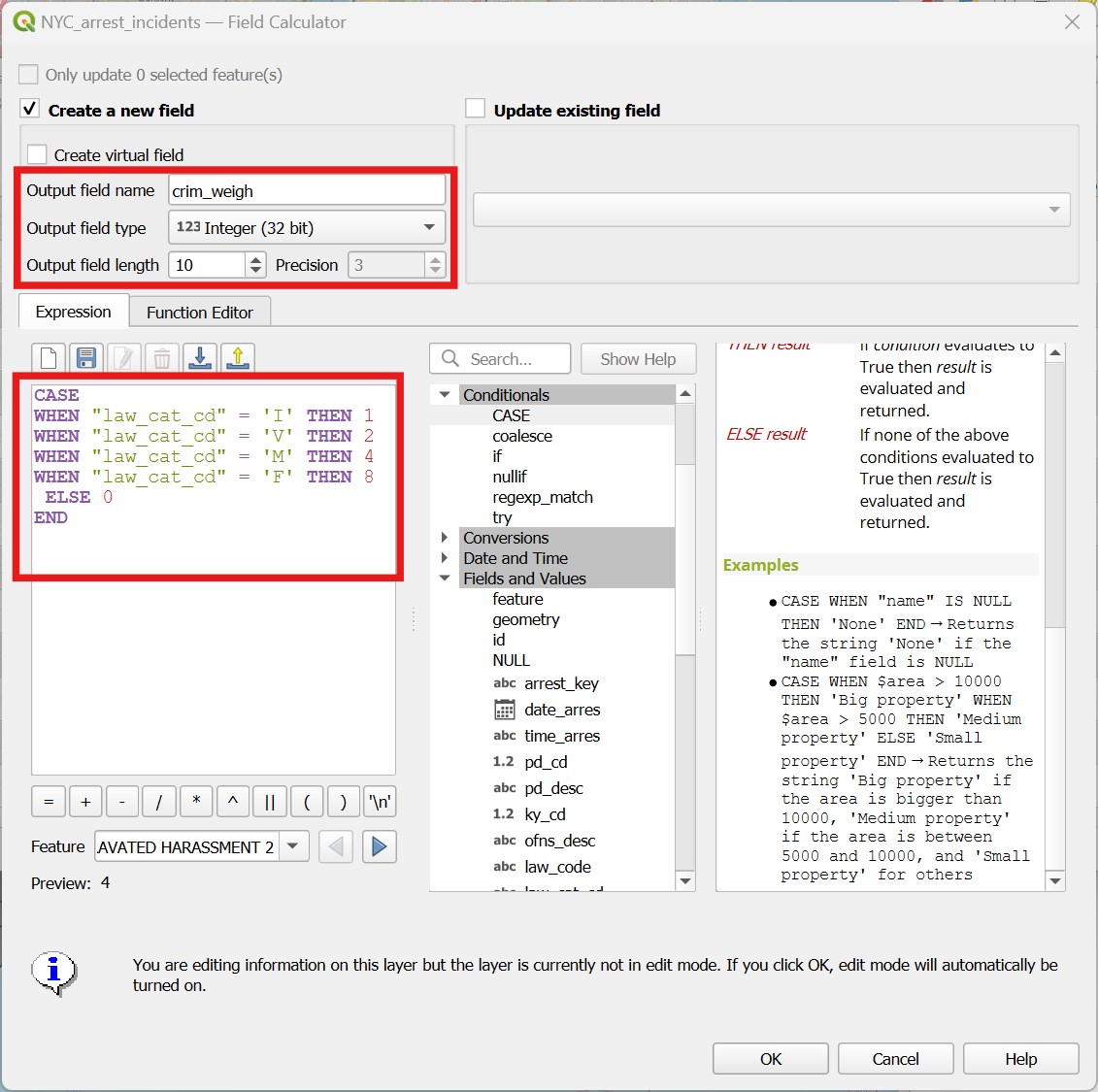
Now repeat the
Heatmap (Kernel Density)calculation you did before, using aradiusof 1000 meters, 50mXandYpixel sizes, theQuarticKernel ShapewithRawvalues, but this time pick the newcrim_weighfield forWeight from Field. Save your results with an informative name such ascrime_density_1km_quartic_50m_weighted.tifand check the results.To facilitate comparison between the original and the new density layer, change the
Singleband PseudocolorsymbologyModefromContinuoustoQuantile, with 10Classes, for both layers.
How much did the results change?
13.4 Guided Exercise 4 - Visualizing densities as isolines
Our density maps are good and informative, but they will hide any layers below them. Isolines or ‘contour lines’ are lines that delineate areas within the same ranges of values - and make for good data overlays. The most common use for them is to indicate topography (see below). Each brown line is associated with an elevation, and some thicker lines are used as reference isolines to facilitate navigation.

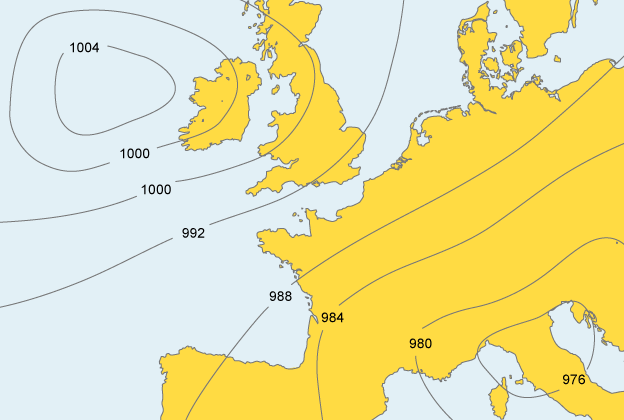
However, we can use isolines to show any type of continuous value surface. For weather prediction, for example, contour lines indicating zones of equal pressure are called isobars :
We can therefore also visualise density maps as contour lines. This has the advantage of making it easier to overlay the hotspots on top of other information. To create an isoline map from our crime hotspots, we have two options, similarly to the heatmaps themselves. The first is to use a Symbology, the second is to create a new layer.
So we don’t lose the original heatmap symbology, right click on the crime density layer and select
Duplicate Layerto make a copy of it. Make sure the layer copy is on top of the original layer.Now select the layer copy you created and go to
Properties > Symbology. Switch the symbology type toContours. The default values for the contours and the index contours are too low (they are set for elevation), so let us use1000as thecontour interval, and2000as theindex contour. Notice how the contour lines align with the hotspots of the original layer.Now turn off the hotpots and make a map that uses only the contours to show the crime hotspots over the OpenStreetMap layer, together with the Neighbourhood layer. Something like this:
- Now turn off this contour-styled layer, and instead go to
Raster > Extraction > Contour.... Pick your crime density layer asInput Layer, and 1000 as theInterval between contour lines. For attribute name, enterDENS, leave the rest as default and save the result asisolines_density.shp. The output should be identical to the symbology option, but it will be a new line vector layer that can be treated as any other layer, and it will have an attribute that can be used to label the lines.
Challenge: can you add labels to the contour lines using the label options in QGIS?
13.5 Guided Exercise 5 - Distance to Hubs
Continuing with our crime analysis, we now want to get insights on possible response times to incidents, based on the distance from police stations. There are different ways to represent and explore distances in GIS, and we already explored one of them: buffers. You can create buffers that represent specific distances, and then use these buffers to count occurrences within the range.
Can you calculate the percentage of crime incidents in the dataset that happened within 1 km of a police station? Hint: Buffer and Count Points in Polygons should do the trick.
But now let’s say we want to know the average distance of a crime incident to the nearest police station. For this, we would need to know the exact distances for each point, and buffers won’t give us that. The tool we want in that case is Distance to the Nearest Hub (Points) tool, in the Processing panel.
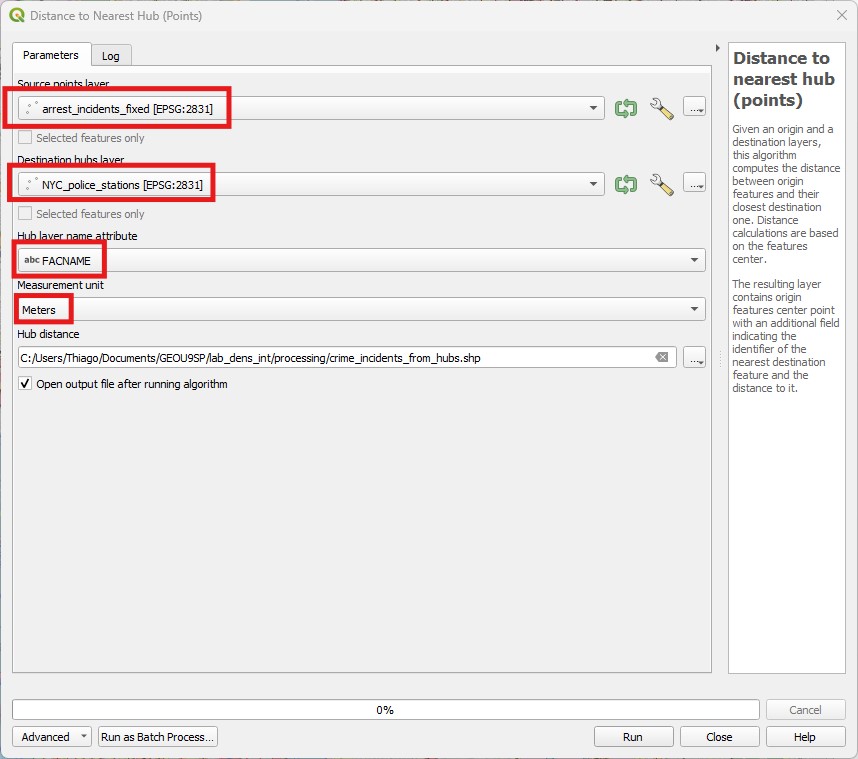
- Open the
Distance to the Nearest Hub (Points)tool in theProcessingpanel. Then pick the crime incident layer as theSource Points Layer, and the police station layer as theDestination hubs layer. PickFACNAMEas the hub layer name attribute (the name of each police station), andMetersas theDistance unit, save it ascrime_incidents_from_hubs.shp, thenRun. It will take a while (after all, QGIS needs to look into each of the 616835 crimes one by one and determine which police station is nearest).
- Now open the attribute table of the new layer your created. It should have all the original attributes of the crime incident layer, plus two new attributes at the end:
HubNameandHubDist. You can then use theSummary Toolto find out the average for theHubDistattribute, and answer the question above (I got 749 meters).
Since the name of the police station is also brought to the table, you could use Statistics by Category (Processing panel) to calculate the total or average number of nearest crime incidents per police station - that could give you insight in how overwhelmed some stations could be in relation to others. Or you could calculate the average distances to each hub, and have an idea of which police stations are responsible for covering the largest distances.
13.6 Guided Exercise 6 - Distance Maps
There are times, however, when you want to create a distance map - a layer that shows how far every location is from some reference point(s). For example, if you were planning the location to install a new wind turbine, you may want to prioritise areas that are closer to a power line. In our crime example, maybe we want to identify regions in the city that are too far away from any police station - and therefore good candidates for creating a new one. The tool for that is called Proximity (raster distance) in QGIS. This tool however only works with rasters, so we need to convert our police stations into a raster first:
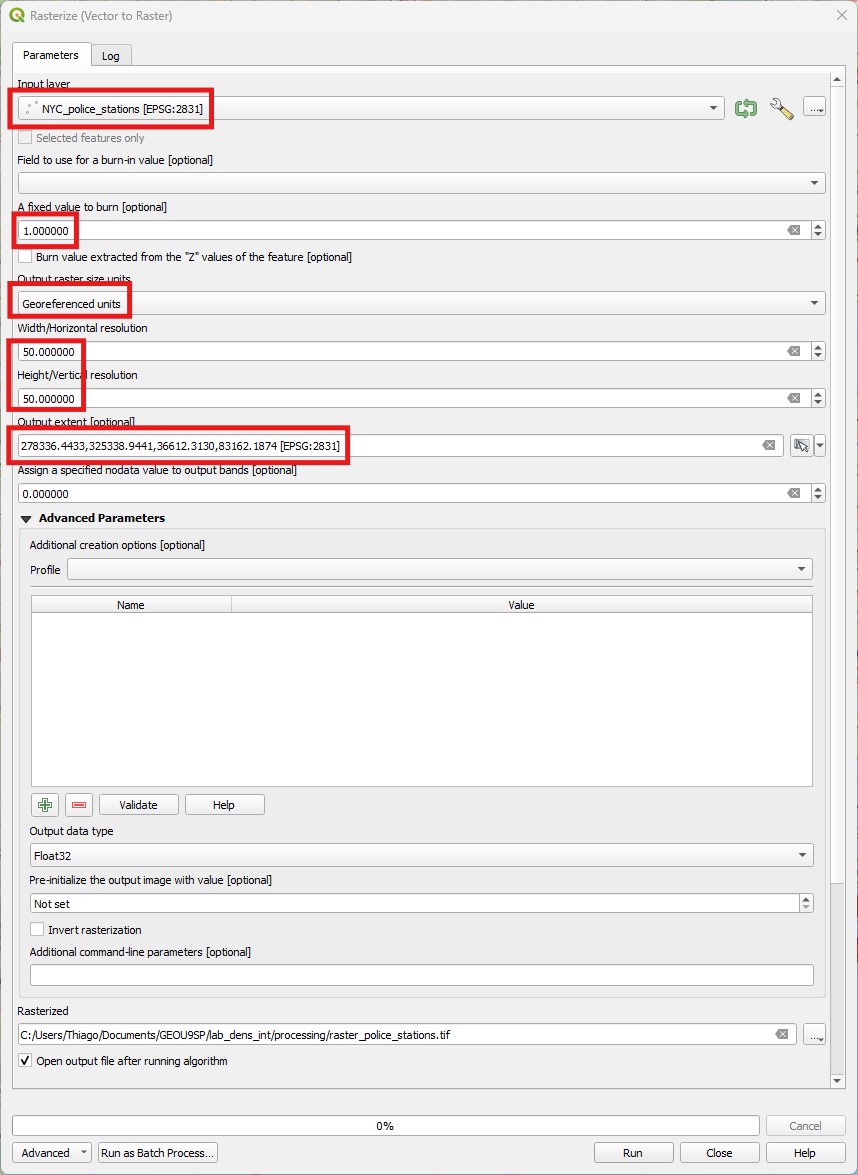
- Go to
Raster > Conversion > Rasterize. Then pick the police stations asInput Layer, and1as aFixed value to burn. Then pickGeoreferenced UnitsforOutput raster size units, pick50for both horizontal and vertical resolution (those would be meters), and set theOutput Extentto match the neighbourhoods layer extent - click on the small down arrow, then pickCalculate from layerand select the neighbourhoods layer. This option determines how large your raster will be. Set theOutput data typetoByte, and then save the result asraster_police_stations.tif. You will get a raster with a pixel value of1‘burned in’ wherever a police station exists, and0(which is the defaultnodataoption, so it will show as such) otherwise. You may need to zoom in to see the dots, but they are there.
- Now open the
Proximity (raster distance)tool in theProcessingpanel, underRaster Analysis. Pick the rasterised police stations as theInput Layer, and add the number1as theList of pixel values....option. Change the distance units toGeoreferenced coordinates, leave the rest as default, and save the output asdist_from_police_Stations.tifandRunit.
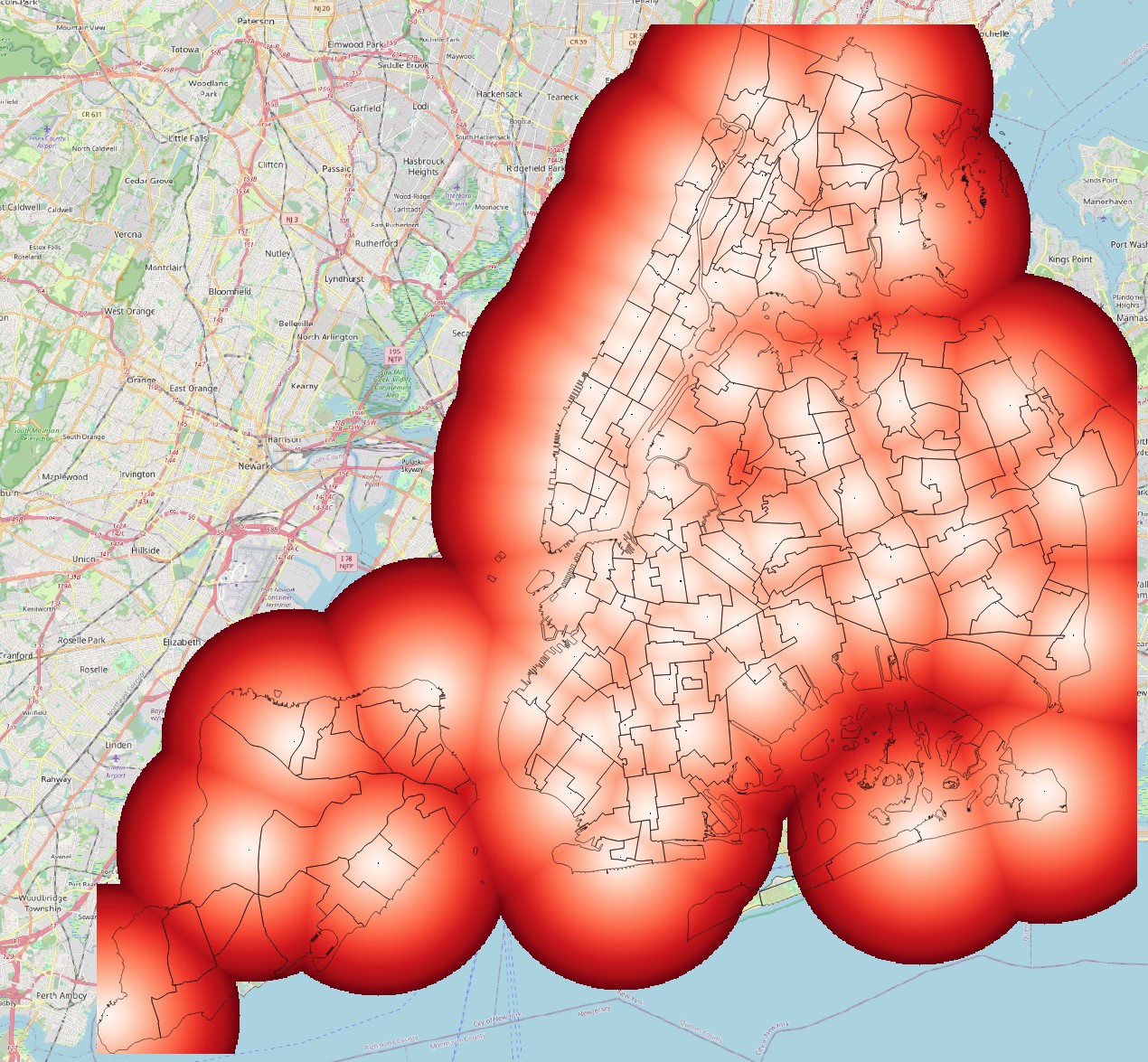
- The resulting layer is a raster map where the pixel values represent actual distances from a police station. Apply the
Singleband Pseudocolorsymbology with theRedscolour palette to it, and then overlay the neighbourhoods vector on it for reference.
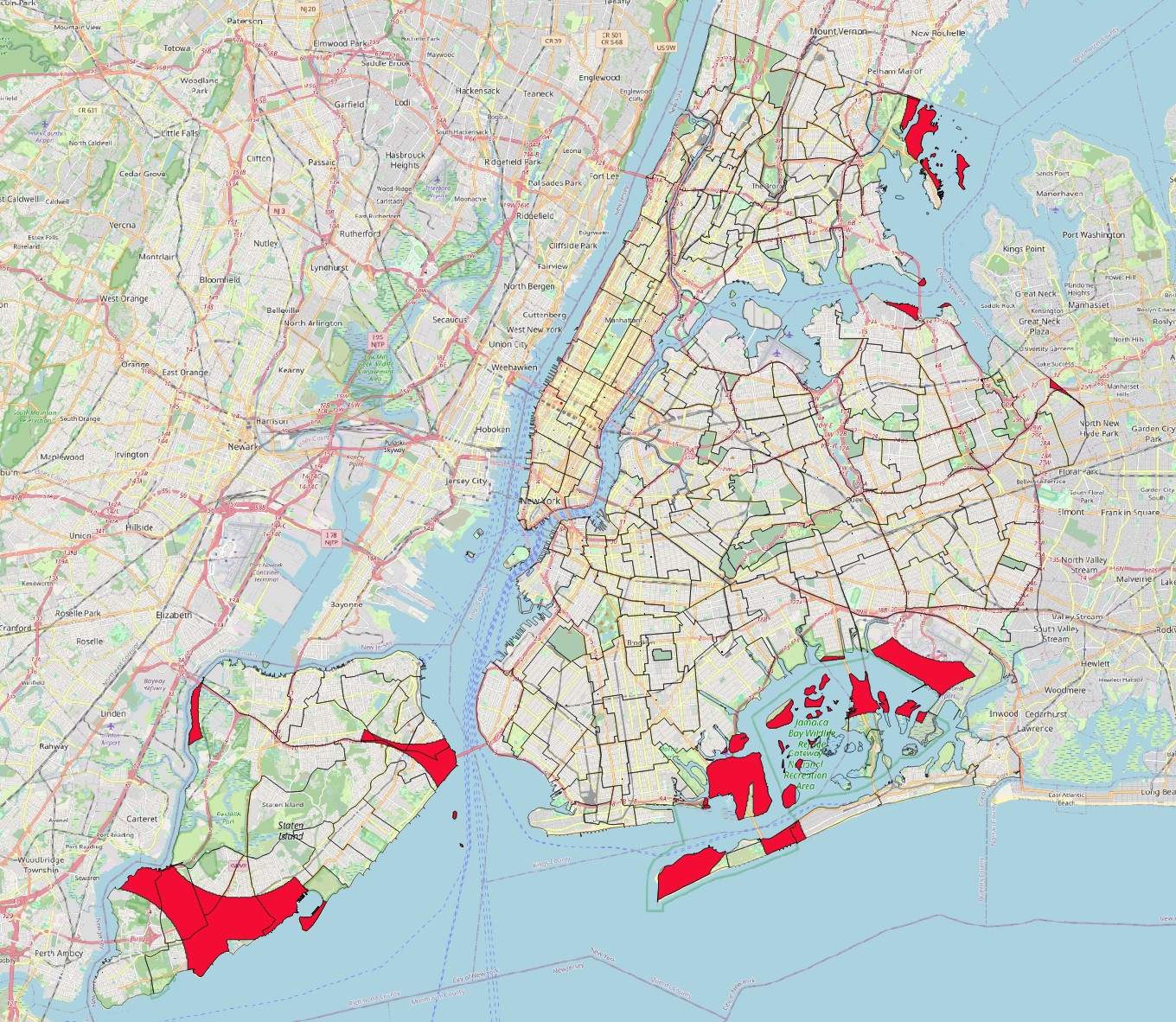
- Let us assume that any area beyond 4km of a police station would be a good candidate for a new station. Use the
Raster calculatorto create a new layer showing only these areas, from the distance map you just created. Then polygonise the results and clip them by the neighbourhoods layer to create vector polygons of ‘Potential New Station Locations’. It should look like this:
Done! This is the end of Lab 13. You now know how to create heatmaps and contour lines, and different tools to work with distances in GIS. In the next lab we will learn some additional distance-based tools, and then practice with an Independent Exercise.